Er zijn weleens variabelen waar we uitspraken over willen
doen, die niet in één keer te meten zijn. Dit omdat een concept bijvoorbeeld te
abstract is (“tevreden”), te complex (“zelfvertrouwen”) of op meerdere manieren
op te vatten is (“geluk”). Er zijn hier veel voorbeelden van en worden vaak in
de literatuur latente variabelen
genoemd. Dit betekent dat de variabele niet
direct te observeren is. In plaats daarvan meet je dit door aan de hand van
een aantal indicatoren. Indicatoren
zijn gewoon weer variabelen. Samen meten de indicatoren een concept / een
latente variabele. Een ander woord voor het geheel samen is een construct.
Werken met een construct in SPSS
In vragenlijsten is een construct vaak opgebouwd uit meerdere vragen die op hun beurt stuk voor stuk die indicatoren meten. In de Nationale Studenten Enquête wordt hier bijvoorbeeld gebruik van gemaakt.
Een voorbeeld uit deze vragenlijst van een construct is Studierooster. Studierooster wordt
gemeten aan de hand van 4 indicatoren: (1) het tijdig bekendmaken van de
studieroosters, (2) het tijdig bekendmaken van wijzigingen in het studierooster
(3) de studeerbaarheid van het studierooster (bijv. spreiding en tijdstippen),
en (4) het aantal in het studieprogramma geroosterde onderwijsuren. Deze vier
vragen worden allemaal beantwoord en uiteindelijk wordt er in de resultaten
gesproken over de tevredenheid met betrekking tot het studierooster en niet over de vier onderliggende variabelen. Hoe
werkt dat?
Opbouw construct
Allereerst wordt een construct opgebouwd aan de hand van
theorie en ervaring van onderzoekers en mensen uit de populatie. Laten we er
vanuit gaan dat deze vier indicatoren inderdaad een bijdrage leveren aan de tevredenheid
met het studierooster. Laten we ook aannemen dat ze alle vier ongeveer even
belangrijk zijn en dat er geen indicator is vergeten. Dan ziet het er schematisch
ongeveer zo uit.
Schematische weergave construct in SPSS
Construct in een vragenlijst
De volgende stap is dat het construct uitgevraagd wordt. In de NSE worden de vier stellingen uitgevraagd met de vraag hoe tevreden de student is. De antwoordopties zijn: 1 t/m 5 1=zeer ontevreden; 5=zeer tevreden; 6=n.v.t.. De 6 wordt na afloop als missing value neergezet (lees hier meer over omgaan met escape opties)
Interne consistentie van een construct
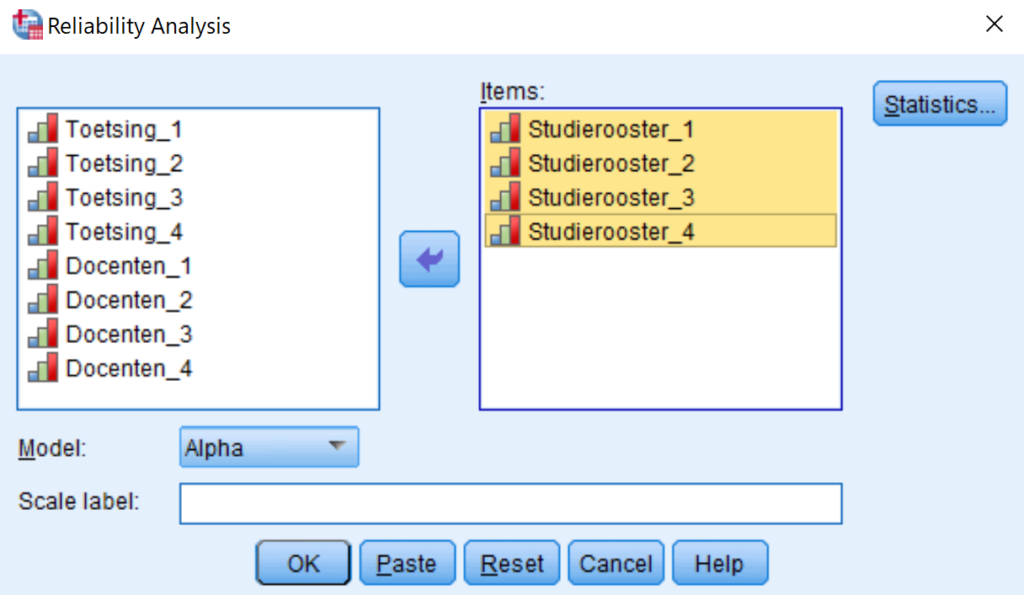
Een van de eerste zaken die je tijdens de analyse moet controleren is of een construct wel intern consistent is. Dit betekent dat je gaat kijken of de vier indicatoren/variabelen wel (ongeveer) hetzelfde meten. Dit wordt ook wel construct validiteitgenoemd. In SPSS kan dit eenvoudig worden berekend door de Cronbach’s Alpha. Deze maat kun je in SPSS vinden in het menu Analyze/Scale/Reliability Analysis… In dit menu geef je aan welke variabelen volgens jou een construct meten en SPSS controleert de interne consistentie aan de hand van de Alpha. Hieronder zie je een screenshot van het menu.
Testen op Cronbach’s Alpha in SPSS
In de regel wordt een Cronbach’s Alpha van 0,7 of hoger gezien als een positieve score. Je kunt dan aangeven dat de onderliggende indicatoren intern consistent zijn.
Berekenen van een construct in SPSS
Nu wil je uiteraard een uitspraak doen over het construct zelf. We hebben van ter voren de (gemakkelijke) aanname gemaakt dat de verschillende onderliggende indicatoren even zwaar wegen. Dit betekent dat we voor elke respondent een score kunnen berekenen via Transform/Compute. Daarmee kun je zelf berekeningen maken (lees hier meer over deze optie) We hebben daarin twee verschillende opties. Geen van de opties is goed of fout, denk wel aan de verantwoording die je opstelt. Het verschil zit hem in hoe je omgaat met respondenten die een variabele niet hebben ingevuld. Stel een student vult slechts 3 van de 4 vragen in… mag deze dan mee in de berekening van het construct?
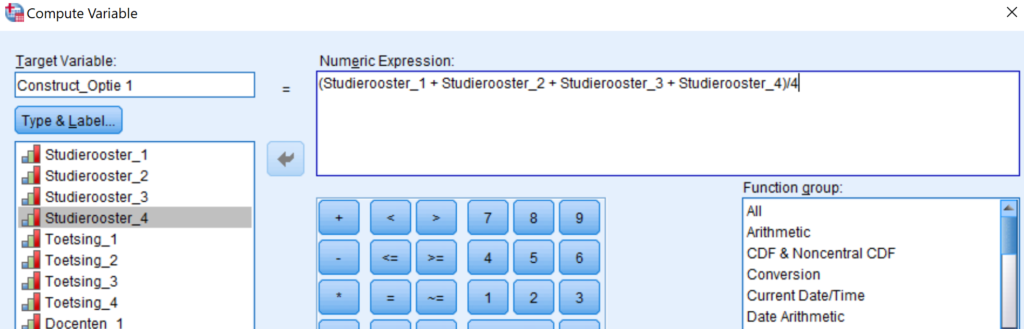
Optie 1 alle indicatoren ingevuld Als je puur een construct wilt berekenen over de indicatoren die zijn ingevuld en de respondenten wilt uitsluiten die 1 van de 4 (of meer) niet hebben ingevuld, maak je gewoon een simpele berekening in Compute. Hieronder zie je de berekening, de 4 variabelen optellen en delen door 4. SPSS neemt dan automatisch geen respondenten mee die missing values hebben in 1 van de 4 variabelen.
Berekenen via compute
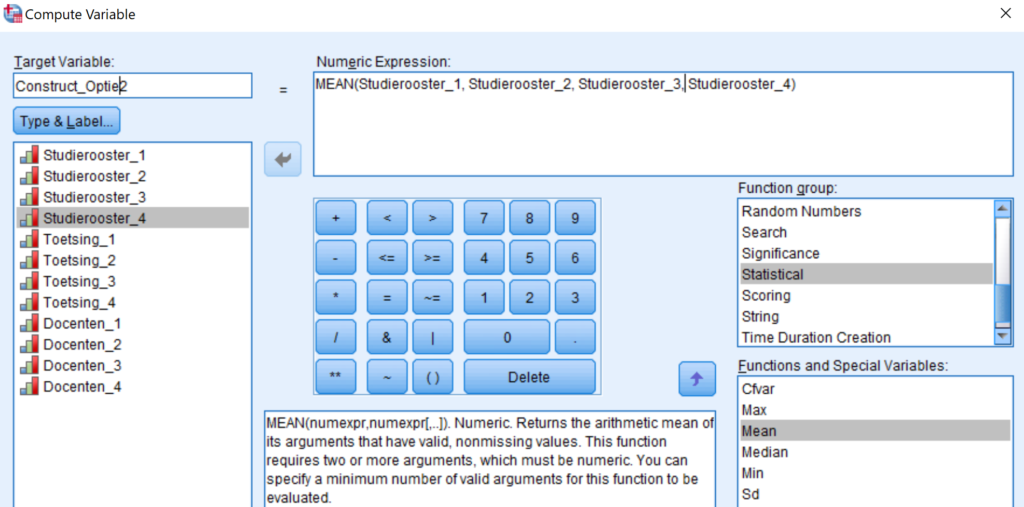
Optie 2 alle respondenten Wil je wel alle respondenten, ook al hebben ze slechts 2 van de 4 ingevuld? Dan moet je kiezen voor de MEAN optie in Compute. Deze kun je vinden onder Function Group: Statistical en Functions and Special Variables: Mean. SPSS berekent dan een gemiddelde over de vier variabelen maar houdt rekening met missing values. Met andere woorden, als iemand er slechts 2 heeft ingevuld, berekent SPSS de totaal score gedeeld door 2. Heeft de respondent er 3 ingevuld wordt het de totaal score gedeeld door 3.
Construct berekenen via Compute
Resultaat
De berekening heeft er voor gezorgd dat je per respondent een constructscore hebt, oftewel de tevredenheid over de studieroosters per student. Nu kun je simpel een gemiddelde berekenen voor de hele dataset. Uiteraard kun je dit voor verschillende opleidingen splitsen, zoals gebeurt bij de NSE. Lees hier meer over het vergelijken van gemiddelden.
Een lang verhaal kort
Een construct wordt in de regel gemaakt voor een concept wat we niet in één keer kunnen observeren / meten. De indicatoren worden over het algemeen samengesteld op basis van theorie en ervaring. Controleer tijdens je analyse altijd eerst of de interne consistentie hoog genoeg is en voeg dan het construct samen. Hierna kun je uitspraken doen over het concept waar jij naar op zoek bent. Succes!
Als schrijver van een verslag heb je veel ballen in de lucht te houden en je wilt het vooral niet verkeerd doen. Zeker niet bij een scriptie. Je gaat dapper op zoek naar veel informatie om je scriptie te vullen. Tientallen (betrouwbare) bronnen en een veldonderzoek met interviews en/of een enquête leveren soms wel honderden pagina’s aan informatie op. En alle informatie is voor jou als schrijver even belangrijk, want je zou misschien wel eens iets kunnen vergeten wat belangrijk is… Dus zit je met je handen in het haar te staren naar die map op je laptop waarin al je informatie staat en je denkt: hoe kom ik in vredesnaam aan een gestructureerd rapport binnen alle eisen van de opleiding?
Een paar tips…
Om je te helpen heeft de SPSSKoning een paar tips op een rijtje gezet, zelf al ruim 10 jaar scriptiebeoordelaar.
1. Een goed begin is het halve werk
Je hebt het vast vaak genoeg gehoord en wellicht ben je er stiekem ook al een paar keer tegen aangelopen… je moet vanaf het begin een goede structuur opbouwen in de wijze waarop je informatie opslaat. Artikelen die je leest, stukken uit boeken die je kunt gebruiken of een goed gesprek waar net dat ene logische puzzelstukje werd uitgelegd. Allemaal zaken die uit je hoofd kunnen verdwijnen na een leuk weekendje weg met wat slaaptekort. Maak er dus vanaf het begin een gewoonte van om belangrijke zaken te noteren en op te slaan. Hiervoor moet je vooral je eigen methodes gebruiken die voor jou prettig werken. Want jij moet het gebruiken. Er zijn natuurlijk genoeg hulpprogramma’s beschikbaar die zorgen dat je je bronnen goed op kan slaan en bewaren (bijvoorbeeld Mendeley). Daarnaast zou je bijvoorbeeld OneNote van Microsoft kunnen gebruiken. Een programma waar je zo even citaten, aantekeningen van gesprekken en meer kunt opslaan per relevante categorie. Persoonlijk was ik zelf altijd van een goede mappenstructuur op mijn laptop (die ik te laat opbouwde), en zorgen dat ik dagelijks mijn materialen even opsloeg (ik was al blij als het mij 1x in de week lukte). Een mappenstructuur waarbij je per deelvraag of per hoofdstuk materialen opslaat en overige mapjes met materialen die je nog wilt gebruiken, zorgt er in ieder geval voor dat je in je eigen systeem zaken terug kunt vinden.
2. Informatie op de
juiste plek
En dan komt dat moment, honderd pagina’s met bronnen, 200
vragenlijsten ingevuld en 15 interviews afgenomen. Hoe nu verder? De
belangrijkste tip daarin is: zet de informatie op de plek waar het hoort. Ga
niet direct beginnen met de vraag of zaken wel relevant zijn in je rapport.
Waar je wel mee moet beginnen is het plaatsen van de informatie waar deze
hoort. Je doet dit aan de hand van je (sub)deelvragen. Hoe beter je in het
begin (bijvoorbeeld in je plan van aanpak) hebt nagedacht over de deelvragen en
sub deelvragen, des te beter kun je nu je informatie neerzetten waar deze
hoort. Zo ontstaat er vanzelf duidelijk per (sub)onderdeel welke informatie er
is en welke informatie er eventueel nog ontbreekt. Je zult ook gaan merken dat
je niet alle verzamelde informatie logisch bij een onderdeel kwijt kan. Blijf
daar eerst niet in hangen. Gooi het even in een mapje overige en ga door met het plaatsen van de informatie. Als je
daarmee klaar bent kun je nog eens kijken naar de overgebleven informatie. Is
dit niet relevant? Of is dit juist super relevant en heb je daar vooraf niet een (juiste) deelvraag
over geformuleerd? Niets aan de hand, dat heet voortschrijdend inzicht. Creëer een plek waar deze informatie wel
tot zijn recht zou komen en verantwoord dit later in je scriptie.
3. Eerst analyseren,
dan concluderen
Dit klinkt heel logisch, alleen de praktijk leert dat veel
studenten hier nog de mist in gaan. Analyseren is iets anders dan concluderen.
Analyseren is ook iets anders dan informatie verzamelen en weergeven. In de
analyse probeer je de informatie die je hebt gevonden (weet je nog: honderden
pagina’s) te reduceren en tot een logisch geheel te brengen. Hiervoor gebruik
je bijvoorbeeld methoden uit modellen of analyse technieken. Je combineert
bronnen en geeft uitgebreid antwoord op de deelvraag. Je maakt per
deelonderwerp een logisch verhaal uit de data/gegevens, zonder direct een
conclusie te trekken. Hoe kun je het verschil het beste in je hoofd houden? Als
je een eigen mening vormt of beschrijft wat er moet gebeuren, ben je aan het
concluderen of advies aan het geven. Houd het nog even voor je.
4. Blijf niet hangen
bij de analyse en de conclusies
Te vaak zien we dat studenten blijven hangen in de analyse.
Ze beschrijven van alles en nog wat en vinden de volgende stap naar conclusies
al heel lastig. Laat staan naar aanbevelingen of advies. Hierin schuilt vaak
onzekerheid. Je hebt alle informatie en nu komt het op eens aan op jou! Maar
geen zorgen, als beoordelaars zijn we juist op zoek naar wat jij kan. We willen
weten welke conclusies jij trekt en welk advies daaruit gaat volgen. Niet omdat
we je willen controleren, maar omdat we nieuwsgierig zijn. In gesprekken met
studenten blijkt keer op keer dat ze heel goed weten wat de belangrijkste
conclusies zijn. Vaak is dat iets anders dan de opdrachtgever had verwacht. En
dat is spannend. Eng zelfs. Maar juist ook waarom jij bent ingehuurd. Als ze
alles al wisten, hadden ze jou niet nodig. Dus laat maar horen die conclusies
en de aanbevelingen of het advies. Ga helemaal los en gebruik de informatie die
je eerder hebt onderzocht om je verhaal te ondersteunen. Introduceer je iets
nieuws? Vergeet dan niet om je verhaal weer te onderbouwen vanuit bronnen.
Vind je het lastig om van veel informatie naar een conclusie te komen? Vraag je dan af of je wel alle deelvragen goed beantwoord hebt (voldoende informatie?). Het kan ook zijn dat je er achter komt dat je niet alle vragen gesteld hebt. Klopt het wel allemaal? Maak dan een mooie mind map. Tekenen helpt. Sowieso helpt iets doen altijd. Als je het niet weet, gewoon aan het werk gaan, het antwoord komt vanzelf.
5. Methode-W
En dan nu de gouden tip om te blijven binnen de eisen van de
opleiding. Maar vooral ook om een fijn leesbare rapportage of scriptie te
schrijven, die bol staat van relevante informatie, scherpe analyses en briljant
en logisch advies. Met andere woorden: die rode draad waar iedereen het altijd
over heeft, loopt als een kloppende levenslijn dwars door je verhaal heen. Hoe?
Methode-W! Je hebt als het goed is tot nu toe alleen in de analysefase
informatie gereduceerd en je niet druk gemaakt om de omvang van je rapportage.
Je hebt geconcludeerd en geadviseerd. Met andere woorden, je bent aan het einde
van “het document”. Nu ga je in de omgekeerde volgorde weer naar boven. Je weet
nu namelijk waar je advies op uitkomt. In je advies maak je gebruik van de
belangrijkste conclusies. Lees dat hoofdstuk nu nog eens, is alles wat daarin
staat nodig om het advies goed te begrijpen? Of kunnen sommige onderdelen
worden ingekort of er zelfs uit? Na deze opschoontaak kun je de
analyse/resultaten fase van je rapport nog eens door. Je hebt nu een scherp
conclusie hoofdstuk. Welke onderdelen zijn relevant uit je analyse/resultaten
om de conclusies te kunnen begrijpen? Nu zul je zien dat er best veel ingekort
kan worden en er ook veel zaken naar de bijlage kunnen. Dan kom je weer bij je
inleiding met de probleemstelling. Klopt dit nog allemaal als je terugkijkt op
wat je gedaan hebt? Kan het korter, moet het anders worden ingestoken?
Herschrijf indien nodig.
Methode W (c) SPSSKoning
Nu je van onder naar boven alles opgeschoond hebt, is het
tijd om het rapport nog eens door te lezen. Het liefst op een andere wijze dan
je gewend bent (dus nu op papier of op een ander device). Nu is ook het moment
om hulp in te roepen van medestudenten, ouders, collega’s etc. Die lezen het
voor het eerst en kunnen opzoek naar de “rode draad” jou nog veel tips geven.
Hoef je het zelf niet te doen dan? Ja juist wel! Jij bent de meester van je
scriptie, de koning van je verhaal en de keizer van de resultaten. Alleen jij
kan beoordelen of wat er staat klopt.
De laatste weg is weer naar boven. Waarom nog een keer? Dit
is een prima methode om je samenvatting / management summary / abstract of hoe
het ook heet, te schrijven. De lezers van de samenvatting zijn vooral
geïnteresseerd in de belangrijkste aanbevelingen en het advies. De daarbij
horende conclusies en hoe je daar toe gekomen bent. Van onder naar boven lezen
en op basis daarvan de samenvatting maken zorgt voor veel minder niet-relevante
info in de samenvatting. Probeer het maar, het werkt echt!
Tot slot – tijd,
tijd, tijd….altijd te weinig
Het lijkt er in dit soort trajecten vaak op dat je aan het
einde van de periode nog een stuk schrijfwerk over houdt in plaats van
andersom. Je hebt altijd te weinig tijd. Vraag jezelf eens af of dat echt zo
is, of dat je dat vooral denkt omdat je bang bent dat het niet goed zal zijn en
je daarom dingen uitstelt? Ik was altijd zo’n uitsteller vanuit onzekerheid. En
dan de laatste weken dag en nacht knallen. Terugkijkend denk je dan altijd dat
er meer uit te halen valt. Vertrouw op jezelf en wees je er van bewust dat bij
99 van de 100 scripties de student altijd meer weet over het onderwerp dan zijn
begeleider en bedrijfsbegeleider. Jij ben 15 tot 20 weken bezig geweest met het
onderwerp. Als beoordelaar zijn we opzoek naar een student die laat zien dat
hij meester is over een onderwerp of probleem, dat zij er goed over nagedacht
heeft en tot logische conclusies komt en keuzes durft te maken op basis van die conclusies. We hoeven
het echt niet altijd met je eens te zijn, maar als je verhaal logisch is van A
tot en met Z, dan ben jij die aankomende professional die op basis van
onderbouwing uit betrouwbare informatie de juiste conclusies kan trekken en
keuzes durft te maken.
De laatste tip is dan ook: ken de zwakheden van de scriptie.
Schrijf een goede verantwoording waarin je aangeeft wat goed en ook wat minder
goed is gegaan. Ga geen dingen verdedigen waarvan je weet dat het niet klopt.
Een professional beschrijft het zoals het is en kan aangeven hoe het de volgende
keer anders zou kunnen.
Lang verhaal kort
Begin op tijd met een goede structuur, zet de informatie
daar waar deze hoort en maak je tijdens de analyses niet druk om de omvang van
je rapport. Ga met de methode-W door je scriptie of rapportage heen en schrijf
een scherp en relevant verhaal.
Heb jij zelf nog relevante tips? Deel ze via de facebookpagina van SPSSKoning.
Het is tijd om het over het wegen van respondenten te hebben. Ik wil het niet te zwaar maken, ondanks dat het een gewichtig onderwerp is. Na de feestdagen heeft iedereen het erover….. Oké, klaar met de woordgrappen.
Het wegen van de (antwoorden) van de respondenten kan een belangrijk onderdeel zijn van het analyseren van jouw onderzoekresultaten. Er zijn meerdere redenen om te wegen. De belangrijkste reden is vaak over- of ondervertegenwoordiging van een groep respondenten binnen de dataset. Dit betekent dat een bepaalde groep mensen (of onderzoekitems) naar verhouding vaker in je onderzoeksgroep zitten dan dat ze zouden moeten zitten. Met andere woorden, je onderzoek is niet representatief! Om te corrigeren voor over- of ondervertegenwoordiging worden respondenten gewogen om de juiste verhoudingen in de dataset te krijgen.
Moet ik wegen?
Een belangrijke vraag, voordat we verder gaan, is natuurlijk of je zou moeten wegen. Om hier antwoord op te krijgen, moet je jezelf twee andere vragen stellen. Allereerst de vraag: is mijn steekproef op kans gebaseerd (stochastisch) en mag ik dus generaliseren? Met andere woorden, wil je een uitspraak doen over een hele groep (oftewel de populatie) in plaats van enkel je respondenten? (de onderzoeksgroep). En mag dat ook? Is aan alle voorwaarden voldaan? Als het antwoord ja is, dan moet je jezelf nog een tweede vraag stellen. Zijn de verhoudingen van mijn onderzoeksgroep gelijk aan de verhoudingen binnen de populatie? Om deze vraag te beantwoorden heb je twee gegevens nodig. Allereerst moet je een (betrouwbare) bron hebben met de verhoudingen binnen de populatie. De data van het centraal bureau voor de statistiek (CBS) biedt hier vaak uitkomst. Daarnaast moet je weten of de verhoudingen binnen jouw dataset ook werkelijk afwijken. Hiervoor gebruik je de Chi-kwadraat toets voor het toetsen van verhoudingen. Wijkt het significant af? Dan zit er niets anders op dan te wegen.
Wegen in SPSS
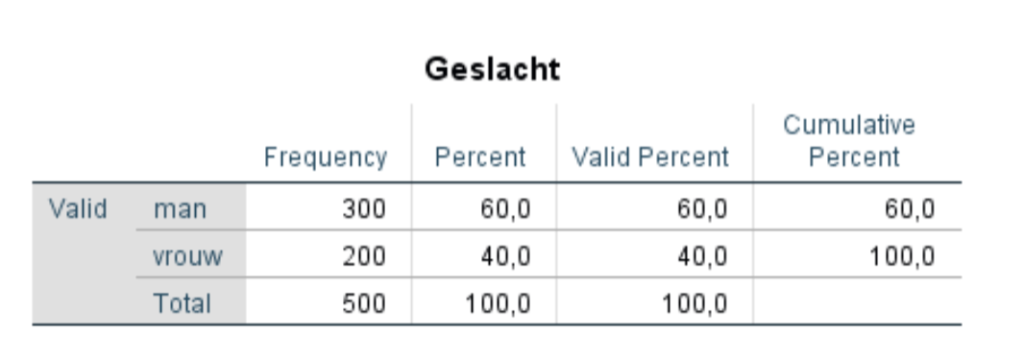
Als voorbeeld nemen we een kijkje in een (aangepaste) dataset van SPSSKoning. Het is een onderzoek onder de studenten van Hogeschool Koning (uiteraard). De verhouding man/vrouw zie je hieronder in de tabel, 60% mannen en 40% vrouwen.
Uit de gegevens van de administratie van de Hogeschool blijkt dat de verhouding man/vrouw op de Hogeschool ongeveer 50/50 is. Aangezien het verschil significant is, moeten we gaan wegen. Om te kunnen wegen in SPSS heb je een weeg-variabele nodig, oftewel een frequency variable. Dit is een variabele waarmee SPSS de antwoorden die de respondenten hebben gegeven kan gaan wegen. Een soort correctie moet er dus plaats vinden.
Om te corrigeren hebben we een correctiegetal nodig. Bij de mannen is dat 50/60 = 0,833 (afgerond) en bij de vrouwen is dat 50/40 = 1,25. Hiervoor gebruik je de valide percentages. Boven de streep komt 50 te staan omdat we willen corrigeren richting de verhouding 50/50.
Controleer je berekening!
Om te controleren of we het juiste hebben gedaan maken we een berekening met de absolute aantallen van onze respondenten (frequency).
We vermenigvuldigen 200 vrouwen met 1,25 (= 250)
En we vermenigvuldigen 300 mannen met 0,833 (= 249,9).
Nu hebben we bij benadering de verhouding 50/50.
Als je vermenigvuldigt met 0,833333333 dan komt het precies uit! We kunnen dus beter met een niet afgerond getal vermenigvuldigen.
We gaan nu een nieuwe variabele maken via Compute. We maken één nieuwe variabele, maar daarvoor moeten we twee opdrachten geven. Allereerst geven we de nieuwe variabele een naam in Target Variable. We kiezen voor de naam: wegen. Dan beginnen we met de eerste opdracht. Bij Numeric Expression geef je de nieuwe variabele de waarde: 0,83, en selecteer je via if (in het venster Compute onderaan te vinden) enkel de mannen (=1). Je rond daarna de opdracht af (via OK).
De eerste opdracht via Compute
Daarna herhaal je deze actie van vooraf aan en geef je de nieuwe variabele (let op, weer wegen invullen bij Target Variable) de waarde 1,25 en selecteer je via if enkel de vrouwen. En ronden we de opdracht af.
De tweede opdracht in Compute
Let erop dat het Compute venster een waarschuwing kan geven als je een komma gebruikt (bij 0,83 of 1,25), ook als je SPSS hebt ingesteld op het komma teken als decimaal teken. Maak dan gebruik van de punt. In de afbeeldingen heb ik beide voorbeelden meegenomen. Zorg dat je de juiste kiest.
Uitkomst van de weging analyseren
De volgende stap is om de analyse te doen en te kijken of de weging inderdaad effect heeft op de uitkomsten. In ons geval zijn we erg nieuwsgierig naar de kosten die studenten per jaar maken voor materialen voor de studie. We maken twee berekeningen. We berekenen het eerst met de weging nog uit. Hiervoor kun je gewoon via descriptives het gemiddelde uitrekenen. Daarna zetten we de weging aan via Data/Weight Cases. Voor de weging kiezen we onze nieuwe variabele: wegen.
Selecteer een weging variabele
Nu de weging aan staat worden alle berekening die SPSS maakt gewogen. Houd hier dus rekening mee bij de interpretatie!
Boven zonder weging, onder met weging
Als we naar het ongewogen gemiddelde kijken (boven) zien we dat de gemiddelde uitgaven rond de 385 euro liggen. Met de weging aan ligt het gemiddelde rond de 377 euro. De weging heeft dus aardig wat impact op het gemiddelde. Het gaat in dit geval om 8 euro verschil en dat klinkt misschien als heel weinig. Maar als je je realiseert dat we 20.000 studenten hebben op Hogeschool Koning en we mogen generaliseren, dan scheelt die 8 euro opeens 160.000 euro in de totale uitgaven. Dat zijn aardig wat pepernoten.
Lang verhaal in het kort
Wegen is soms noodzakelijk om een goede uitspraak te doen over de populatie. Mag je uitspraken doen over de populatie en zijn de verhoudingen in je dataset niet representatief? Corrigeer dan met een weging in SPSS. Controleer altijd de weging en vergeet deze niet te vermelden in je onderzoek- en analyseverantwoording.
Veel succes met SPSS (en til er vooral niet te zwaar aan)!
Het maken van een goede vragenlijst is ontzettend lastig. En deze dan ook nog goed online krijgen blijkt vaak een struikelblok. Zonde als daardoor niet de juiste informatie bij de juiste groep wordt achterhaald. Een van de mogelijkheden die (te) weinig wordt gebruikt door mensen die hun eigen vragenlijst uitzetten (bijvoorbeeld studenten en kleine bedrijven) is het maken van routes. Verschillende routes door een vragenlijst heen voor verschillende groepen respondenten. Terwijl dit juist zorgt voor kwalitatief goede informatie en een respondent die enkel vragen hoeft te beantwoorden die nuttig en logisch zijn. En het maken van de routes heb je zo aangeleerd.
Routes maken in vragenlijsten?
Laten we eerst eens stil staan bij wat het is, routes maken in vragenlijsten. Stel dat er verschillende subgroepen te onderscheiden zijn die jouw vragenlijst kunnen invullen. En dat het interessant is om verschillende groepen, verschillende vragen te stellen. Bijvoorbeeld klanten tegenover niet klanten. Maar er zijn ook andere criteria die je kunt gebruiken om verschillende vragen te stellen. Een paar voorbeelden:
Leeftijd (jongeren vs. ouderen)
Laatste aankoop (recent vs. meer dan een maand geleden)
Aankoopkanaal (fysiek in de winkel vs. online)
Klantcontact (wel contact gehad vs. nooit contact gehad)
Nieuwsbrief abonnee (wel vs. niet)
Wat het ook is, er is vaak een reden om specifieke groepen binnen jouw vragenlijst een bepaalde vraag wel (of juist niet) te stellen. En dan wil je niet dat andere respondenten die vraag ook invullen. Zeker als het niet relevant is voor die doelgroep of als ze er geen ervaring mee hebben. Als je specifieke wensen hebt over wie welke vraag te zien krijgt, zijn er dus verschillende routes die je door de vragenlijst heen wilt leggen. Sommige zien alle vragen, sommige zien slechts de eerste twee vragen en zijn dan al klaar. Wat jij wilt! Er kunnen twee routes zijn of veel meer. Belangrijk is dat jij dit goed uittekent voordat je de vragenlijst gaat maken. En ik schrijf bewust het woordje “uittekenen” op, want dat heeft mij in het verleden altijd goed geholpen.
Voorwaarden voor routes
De optie om routes te maken in online vragenlijsten is er al heel lang. Ook in de gratis versies. En toch zien we in weinig vragenlijsten dit terug. Sterker nog… we zien in veel vragenlijsten dat er niets eens gebruik wordt gemaakt van pagina’s in de vragenlijst. Alle vragen op één pagina in een lange lijst. Super onoverzichtelijk en niet echt gebruiksvriendelijk. En dan kun je uiteraard geen route maken. Een voorwaarde om routes te maken is dat je pagina’s gaat inbouwen in je vragenlijst. Hierdoor zorg je ervoor dat de respondent na pagina 3 bijvoorbeeld naar pagina 5 springt en pagina 4 overslaat. Zonder pagina’s gaat dit nooit gebeuren. Een andere voorwaarde om routes te maken is dat je selectievragen opneemt die voldoen aan de volgende eisen:
Gesloten vraag met antwoordopties
Maximaal 1 keuze voor de respondent
Het programma achter de vragenlijst heeft een criteria nodig om iemand wel of niet door te sturen naar de volgende pagina. Bij een vraag met meerdere antwoorden mogelijk is het onmogelijk om het programma uit te leggen wanneer iemand wel of niet door mag. Houd het dus simpel. En dat begint al bij goed nadenken over wie je subgroepen zijn en waarom zij een andere route moeten bewandelen. Soms is dat heel simpel. Als iemand niet gebeld heeft met jouw klantenservice, kunnen ze deze ook niet beoordelen!
In het voorbeeld hieronder zie je een hele simpele route. Vraag 1 is de selectievraag (bijvoorbeeld: heb je online of telefonisch je laatste bestelling geplaatst?). Hierbij geeft respondent 1 aan dat hij dit online heeft gedaan, daardoor weet het programma dat hij door mag naar vraag 2 (beoordeling bestelling online) en dat hij vraag 3 niet mag zien (beoordeling bestelling telefonisch). Bij de andere twee respondenten is het antwoord op vraag 1 telefonisch. Zij mogen vraag 2 dus niet zien, maar vraag 3 juist wel. Bij vraag 4 komt iedereen weer terug bij elkaar.
Bouwen van de routes
Het bouwen van de routes wordt in de instructievideo voorgedaan in twee verschillende programma’s. Het is niet toevallig dat dit dezelfde zijn als die het beste uit de vergelijking van gratis online enquête software kwamen. Het principe van het bouwen van de route is overal hetzelfde. Het begint bij goed nadenken over de subgroepen, uittekenen van de routes en daarna pas zorgen dat ze goed in de online omgeving staan.
Klaar – testen maar!
Zoals bij elke vragenlijst dient er getest te worden en het liefst met een paar respondenten uit de doelgroep voor de vragenlijst. Nu heb je een extra test element, namelijk het testen van de verschillende routes. Neem dit serieus, als een doelgroep de verkeerde afslag neemt, krijgen ze de verkeerde vragen. Of ze vullen de verkeerde vragen in, of ze haken af. In beiden gevallen gaat het ten kosten van je validiteit en verlies je waardevolle informatie van je respondenten. Bijkomend effect is dat de respondent ook nog eens geïrriteerd is over jouw vragenlijst. Neem het serieus, neem de tijd. En zorg ervoor dat een respondent altijd contact kan opnemen indien er iets mis is met de vragenlijst. Respondenten zijn vaak betrokken bij het merk/de onderneming en vinden het fijn om iets te kunnen helpen. Mocht je onverhoopt er toch een foutje in hebben staan, zij zijn vaak er snel bij om jou te helpen!
Kortom, zorg voor de beste informatie bij de juiste personen door met routes te werken in vragenlijsten. Het verhoogt de kwaliteit van informatie en de respondent krijgt enkel de vragen die hij of zij moet krijgen. Iedereen blij. Succes met het maken van de vragenlijst. Kom je er niet uit, mag je altijd contact opnemen met de SPSSKoning.
Het doen van experimenten als onderzoekmethoden is de laatste jaren veel populairder geworden bij studenten voor een stage of afstudeeronderzoek. Waar er eerder altijd de keuze was tussen interviews en enquête onderzoek, ontdekken steeds meer studenten hoe ze stapsgewijs verbeteringen kunnen doorvoeren voor hun opdrachtgever via A/B-testing.
Mocht je onbekend zijn met deze term: A/B-testing is een methode waarbij je de (potentiële) doelgroep twee verschillende uitingen laat zien en meet welke effectiever is. Online wordt dit veelvuldig toegepast met landing pagina’s, nieuwsbrieven, teksten en knoppen op pagina’s, cross selling, en nog veel meer.
De reden waarom deze wijze van experimenteren een vlucht neemt is omdat veel e-mail en websitetools ook deze mogelijkheid bieden om dit gemakkelijk uit te voeren. Echter bieden deze tools slechts beperkt inzicht in de betrouwbaarheid van de uitkomsten. Die betrouwbaarheid is wel zeer belangrijk om de volgende stap te bepalen en echt goed advies te geven. En niet te vergeten, voor een goede onderbouwing in je scriptie of stagerapport. SPSS kan je helpen om de juiste conclusies te trekken, zodat ook jij betrouwbaar en professioneel overkomt. In deze blog staat omschreven hoe je A/B-testing opzet in de praktijk, hoe je het uitvoert en uiteraard hoe je de uitkomsten interpreteert. Dit alles met behulp van een case.
Visuele afbeelding A/B-test
Opzetten A/B-test
Het mooie van A/B-testing is dat je er direct mee in de praktijk kunt beginnen. Er zijn een aantal stappen die je moet doorlopen om dit methodologisch op de juiste wijze te doen.
Basisstappen
Stap 1
huidige situatie in kaart brengen, inclusief doelstellingen
Stap 2
aannames formuleren (ook wel hypothesen genoemd)
Stap 3
experiment uitvoeren
Stap 4
resultaten interpreteren; en
Stap 5
nieuwe aannames formuleren voor een volgend experiment
In de eerste stap ga je een aantal zaken vooraf bepalen (al dan niet samen met je opdrachtgever). Je begint uiteraard altijd met een doel. En die kan voortkomen uit een probleem of uit een ambitie. Zorg ervoor dat dit doel meetbaar is met de data die op dit moment al wordt verzameld. Als dit niet het geval is, dan moet je eerst gaan achterhalen op welke wijze je de data kan gaan verzamelen. Sta stil bij welke variabelen er allemaal een rol kunnen spelen in het hoofddoel.
Laten we als voorbeeld eens nemen dat er een probleem is dat de nieuwsbrief matig wordt geopend. Gaat het dan om het openen van de nieuwsbrief (open rate) alleen of spelen meer variabelen een rol? Zoals bijvoorbeeld doelgroep of specifieke momenten of acties waar de verbetering moet plaats vinden? Maak het zo nauwkeurig mogelijk. In ons voorbeeld kijken we naar de huidige doelgroep/nieuwsbrief ontvangers.
Nadat je de variabelen in kaart hebt gebracht zet je op een rij wat er allemaal van invloed kan zijn op het openen van een nieuwsbrief. Dit zijn de knoppen waar je straks aan kunt draaien in een experiment. Zo is er bijvoorbeeld verzendmoment, onderwerpregel, content, verzendfrequentie en nog veel meer.
Nu je de huidige situatie en de doelstelling goed in beeld hebt gebracht maak je in de de tweede stap aannames (ook wel hypothesen genoemd). Bij een hypothese spreek je de verwachting uit dat als je (bijvoorbeeld) het verzendmoment van vrijdag naar woensdag verplaatst de nieuwsbrief vaker geopend wordt. Het is belangrijk dat je met A/B testing maar aan één knop gelijk gaat draaien en pas bij een volgens experiment aan een andere knop. Het kan dus zijn dat je meer aannames hebt, omdat je aan meer knoppen wilt draaien. Zet ze in volgorde van waarschijnlijkheid en begin met degene waar je de meeste winst verwacht. Nu je weet wat je doel is (hogere open rate), bij wie (de hele doelgroep) en aan welke knop je gaat draaien (verzendmoment) ben je bijna klaar voor je experiment. Je moet nu de groep aan wie je de nieuwsbrief gaat verzenden nog in twee groepen splitsen. De controle groep (alles blijft bij het oude) en de experimentele groep (ander verzendmoment). Dit kan vrij eenvoudig in verschillende mail programma’s, maar je kunt natuurlijk ook zelf de groepen splitsen. Daarna kun je de derde stap uitvoeren: het doen van het experiment.
Basiskennis voor de juiste conclusie
Nu je data aan het verzamelen bent is het goed om alvast vooruit te kijken naar stap 4: het interpreteren van de resultaten. Bij het doen van experimenteren hoort ook de basiskennis om een toets te interpreteren. Hiervoor kijken we naar significantie. Is een gevonden verschil (in bijvoorbeeld open rate) ook daadwerkelijk een verschil en is deze niet ontstaan door toeval? Hoe weet je zeker dat een gevonden verschil ook betrouwbaar is, zodat je niet de verkeerde conclusie trekt?
Er spelen een aantal zaken een rol die een uitkomst kunnen beïnvloeden. Door statistisch te toetsen (met een significantietoets) probeer je met hoge betrouwbaarheid toeval uit te sluiten. Met andere woorden, je probeert een zo hoog mogelijke zekerheid te hebben dat jouw uitspraak straks betrouwbaar is. Hoe betrouwbaar? De grens van betrouwbaarheid bepaal je zelf. In de praktijk is 95% betrouwbaarheid gangbaar. Dit betekent dat als je nog 100x het experiment zou doen, er 95x dezelfde conclusie uit getrokken zou worden. Dat is al erg betrouwbaar. Er wordt ook vaak gebruik gemaakt van 90% en 99%. Lager wordt gezien als niet betrouwbaar!
Dan is er nog de keuze van de significantietoets die je nodig hebt. In dit geval gaat het om het vergelijken van twee groepen abonnees die allemaal de keuze maken om wel of niet de nieuwsbrief te openen. We spreken daarom wel over een dichotome / binominale variabele. Om deze op verschil te toetsen kunnen we de Chi-kwadraat (pearson) toets gebruiken. Om te vergelijken met een gemiddelde kunnen we Chi-Kwadraat (one sample)gebruiken. Wat heb je nodig om conclusies te kunnen trekken? In ieder geval de data per ontvanger (abonnee). Dit moet je kunnen inlezen in SPSS en dan kun je op basis van de toets kijken welke antwoord je experiment oplevert. En kun je op de juiste wijze conclusies trekken. Hiervoor heb je kennis nodig van hypothesen en significantie.
A/B-test: een case
Om je een beeld te geven hoe de stappen er in de praktijk uit kunnen zien, werken we de case verder uit. Even opfrissen: ons doel is een hogere open rate van de nieuwsbrief, bij de gehele doelgroep.
Stap 1: Huidige situatie en doelstelling
De nieuwsbrief wordt één keer per week aan de hele groep abonnees (n=478) verzonden. Het afgelopen half jaar was de open rate met 37% vrij stabiel. Geen lage open rate, maar de ambitie van de ondernemer is om minimaal boven de 50% uit te komen. In de afgelopen twee jaar had hij vooral de focus om een klantengroep op te bouwen en nu verschoof zijn focus naar het meer stimuleren van herhalingsaankopen. De content van de nieuwsbrief bestaat regelmatig uit twee of drie producten die worden uitgelicht met een call to action. Over het algemeen hangt er een promotie aan minimaal één product. De promotie is soms op prijs gericht, maar wordt voldoende afgewisseld om het interessant te houden.
Stap 2: Aannames (hypothesen)
Op basis van een nieuwsbriefanalyse van het afgelopen jaar (met de focus op de open rate), zijn er twijfels over twee variabelen: de onderwerpregel en de verzendfrequentie. De onderwerpregel was vaak vrij traditioneel (nieuwsbrief week 23: product x). De frequentie van één keer in de week lijkt niet te passen bij het type product (mode gerelateerd). De aanname is dat er met een actiegerichte onderwerpregel al snel wat gewonnen kan worden. En anders wel met een verlaging van de frequentie. We beginnen met het uitvoeren van een experiment voor de onderwerpregel.
Stap 3: Experiment
Het experiment vond plaats in week 34. De controle groep kreeg een vrij traditionele onderwerpregel en de experiment groep een actiegerichte. Hieronder de resultaten.
Op het gevoel zie je hier meteen dat het beter gaat met de experimentele groep dan met de controle groep. Het totaal van week 34 ligt ook boven het gemiddelde van 37%. De volgende stap is nu om te kijken of deze resultaten ook daadwerkelijk significant zijn (zonder toeval), zodat we betrouwbare conclusies kunnen trekken.
Stap 4: conclusies trekken
Om conclusies te trekken moeten we de data inlezen in SPSS. Bij dit experiment kunnen we meerdere vergelijkingen maken. In de tabel hieronder staan 4 vergelijkingen die interessant kunnen zijn. Daarnaast zie je de significantiewaardestaan. Een uitkomst die SPSS genereert om jou te vertellen of er een duidelijke winnaar is en in hoeverre je een betrouwbare uitspraak kunt doen. Met deze informatie kun je per vergelijking een winnaar uitroepen en een conclusie trekken. Laten we naar de vier vergelijkingen kijken:
We zien drie conclusies en die worden getrokken aan de hand van de significantiewaarde. Een korte uitleg (lange versie lees je hier) van de significantiewaarde: een waarde van 0,05 of lager betekent een betrouwbaarheid van 95% (oftewel 0,95). Zoals je ziet telt het samen op tot 1 (0,05+0,95) of tot 100% (5% + 95%).
Hierdoor kunnen we drie winnaars aanwijzen met 99% betrouwbaarheid. De totale open rate van week 34 is hoger dan het gemiddelde (37%), (2) de onderwerpregel die actiegericht is doet het echt beter dan de traditionele en (3) de experimentele groep had een veel hogere open rate dan gemiddeld. De andere conclusie is dat de controlegroep niet afwijkt van het gemiddelde. Dat is een fijne constatering, anders zouden de eerdere conclusies niet kloppen. Onze conclusie, met 99% zekerheid, is dat de actiegerichte onderwerpregel het beter doet dan gemiddeld als het gaat om open rate.
Stap 5: nieuwe aannames formuleren en verder experimenteren
De volgende stap is om te kijken of we nog een verbetering door kunnen voeren met behulp van een experiment. De tweede aanname is dat de verzendfrequentie van invloed is. Iedereen heeft in week 34 een nieuwsbrief ontvangen. Laten we de helft van de groep in week 35 mailen en de andere helft in week 36. Omdat de nieuwsbrief gelijk is in de twee verzendingen kunnen we de groepen met elkaar vergelijken!
Hieronder de resultaten van het tweede experiment. Daarin staan (1) een gemiddelde open rate van de beide momenten samen (2) Week 35 alleen en (3) week 36 alleen. Opvallend is dat in week 35 de open rate weer terugzakt naar het oude gemiddelde, ondanks dat we daar een actiegerichte onderwerpregel hebben gebruikt. Het gemiddelde van de twee nieuwsbrieven samen ligt hoger dan het oude gemiddelde (37%) en week 36 doet het bijzonder goed met 54%.
Stap 6: conclusies trekken
Dit experiment levert wederom veel verschillende vergelijkingen op. De meest interessante vergelijkingen staan hieronder in de tabel. Wederom weer met de significantiewaarde, betrouwbaarheid en de winnaar.
We kunnen nu met zekerheid (betrouwbaarheid) onze conclusies trekken. Een verzending na twee weken doet het beter dan een verzending na één week dan het gemiddelde van week 34 (met 99% betrouwbaarheid). Daarnaast zien we dat week 36 het beter doet dan week 34, beide met een actiegerichte onderwerpregel (met 95% betrouwbaarheid). Interessant is dat week 35 het significant slechter heeft gedaan (99% betrouwbaarheid) dan de experimentele groep in week 34. En we zien dat gemiddeld genomen er geen verschil zit tussen de combinatie week 35/36 en week 34. Dit levert de volgende conclusies op:
Twee keer een actiegerichte onderwerpregel na 1 week verzenden lijkt een negatief effect te hebben.
Twee keer een actiegerichte onderwerpregel na 2 weken verzenden lijk een positief effect te hebben.
Uiteraard ga je nu door experimenteren met de tweede conclusie om te kijken of de open rate rond de 54% blijft.
Betrouwbaar experimenteren
We hebben besproken dat het uitvoeren van A/B testen steeds vaker als onderdeel van stage en afstudeeronderzoeken wordt gebruikt. Logisch, want het is in de praktijk vrij gemakkelijk te organiseren en de resultaten helpen de opdrachtgever direct verder. Verschillende tools geven je vrijwel direct de uitkomsten. Om methodologisch goed te handelen en betrouwbaar te handelen is je basiskennis in hypothesenformulering en significantietoetsen belangrijk. SPSS neemt de meest ingewikkelde zaken voor je uit handen. Aan jou om op de juiste manier de juiste conclusie te trekken. Blijf betrouwbaar experimenteren en je bent al snel een Koning!
Er zijn vele (gratis) programma’s op de markt die je als student goed kunt gebruiken om je vragenlijst af te nemen. Waarschijnlijk zijn er alweer nieuwere programma’s als je dit onderdeel leest. Bedenk van ter voren goed waar een online enquête tool aan moet voldoen. Ik zet een paar criteria voor je op een rij en geef daaronder een aantal tips.
Aantal respondenten die de vragenlijst gaan invullen
Aantal vragen dat je gaat stellen
Soorten antwoordopties die je wilt gebruiken
Inbouwen van routes (bijvoorbeeld: bij nee, ga naar vraag 12)
Look & feel (hoe ziet het er uit)
Responsive (ook goed in te vullen op tablet/smartphone)
Databestand beschikbaar in Excel of SPSS
Al deze criteria spelen een rol bij de keuze van de juiste software. In de tabel de software waar vaak naar verwezen wordt. De vergelijking is voor de gratis versie. De Koning heeft een duidelijke favoriet. Onder de tabel beschrijf ik de online enquête tools. Deze beschrijvingen zijn op basis van mijn eigen ervaringen. Doe zelf ervaring op en maak je eigen keuze.
Vergelijking software voor online vragenlijsten
De twee tools die het beste uit deze vergelijking komen zijn Thesistools.com en Google Forms. De SPSS Koning heeft een voorkeur voor Thesistools.com, want er kleeft een groot nadeel aan Google Forms als de antwoorden overgezet moeten gaan worden naar SPSS.
Thesistools.com
Deze website is al jarenlang een ondersteuner van studenten die voor het afstuderen of projecten een online enquête uitzetten. Over het algemeen is de grens van 500 respondenten meer dan genoeg. En zo niet, is er altijd de mogelijkheid om nog een vragenlijst aan te maken en weer 500 respondenten te verzamelen of een klein bedrag bij te betalen per 500 respondenten. Het aantal vragen dat je kunt stellen en het aantal pagina’s is onbeperkt. Grootste plus is dat dit een van de weinige tools online is waarbij het maken van routes gratis beschikbaar is. Het minpunt is dat de enquêtes vrij basis worden opgemaakt. Het ziet er allemaal niet zo modern uit, maar het werkt wel heel goed. Je kunt je databestand in Excel downloaden en met mijn instructies zou je zo in SPSS aan de slag moeten kunnen. Voor een kleine bijbetaling wordt jouw Excel door thesistools.com zelfs omgezet naar een SPSS bestand. Dus ook dat kun je uitbesteden. Daarmee komen we meteen bij de reden waarom Thesistools.com beter scoort dan Google Forms. De ondersteuning van deze website is erg goed en Nederlandstalig. De opties waarvoor je kunt bij betalen heb je in de regel alleen nodig als je iets extra’s wilt en dan zijn de prijzen zeer schappelijk als je die vergelijkt met de concurrenten op de markt. Google biedt deze extra opties niet.
Google Forms
Een goede tweede keuze, en wellicht eerste keuze als het uiterlijk van je vragenlijst erg belangrijk is voor je. Een groot pluspunt van Google Forms is dat je ook e-mailadresbestanden er in kunt laden en via het programma kan verzenden. Het grootste minpunt is dat de website nog altijd ingesteld is voor Engelstalige gebruikers en zo krijg je bij de optie: anders, namelijk, het Engelstalige other te zien. Best slordig in je Nederlandse vragenlijst. Zoals eerder gesteld is de ondersteuning van Google Forms niet echt aanwezig. Uiteraard kun je online veel uitleg vinden (waarvan de meeste weer in het Engels). Google biedt ook de mogelijkheden om grafieken te maken van de vragen. Dit is vrij beperkt mogelijk (selecties draaien is erg ingewikkeld), maar geeft grafisch wel mooiere grafieken dan SPSS. Er zijn plussen en minnen om Google Forms te gebruiken, ik raad het ook zeker niet af als je opzoek bent naar een gratis tool.
Survio
Opkomende software de laatste jaren onder studenten. De mogelijkheden worden echter steeds meer beperkt. Het is een van de mooiere tools en je maakt echt indruk met een professionele vragenlijst met veel mogelijkheden. Echter kun je slechts 100 vragenlijsten ontvangen, en als dat al genoeg is, kun je het databestand niet downloaden en zul je dus je (mooie) grafieken moeten maken in het programma van Survio. Hoewel erg mooi…een leuke analyse kun je er niet mee draaien.
SurveyMonkey
Naar deze website wordt vaak verwezen door docenten op Hogescholen. Eigenaardig, want met de gratis versie kan je eigenlijk vrijwel niets en met de goedkoopste betaalde versie kan je ook amper wat. Het is leuk om te oefenen met deze software om een vragenlijst te maken. Maar je kunt maximaal 10 vragen stellen en er zit een maximum op 100 respondenten. Erg lastig is het dat je geen routes kunt bouwen en ook een databestand downloaden zit er niet in. Ik raad deze software dan ook zeker af.
We gebruiken cookies om ervoor te zorgen dat onze site zo soepel mogelijk draait. Als je doorgaat met het gebruiken van deze site, gaan we er vanuit dat je ermee instemt.