Google Forms is een van de meest populaire manieren voor studenten om hun (afstudeer)onderzoek uit te zetten. En waarom niet? Het heeft veel voordelen zoals we eerder benoemde in het blog over gratis online enquête software. Maar er kleeft een groot nadeel aan Google Forms als de antwoorden overgezet moeten gaan worden naar SPSS. In de spreadsheet van Google (of Excel) worden de antwoorden vooral tekstueel weergegeven. Dit terwijl veel enquêtesoftware de antwoorden automatisch codeert zodat programma’s als SPSS hier beter mee om kunnen gaan. Dit maakt het ingewikkelder om een vragenlijst in Google Forms om te zetten naar SPSS.
Ingewikkelder, maar niet onmogelijk! We zien twee problemen waar studenten veel tegen aanlopen en deze worden in dit blog met behulp van tekst en video voor je opgelost. De twee problemen zijn:
1) Tekstuele antwoorden overzetten naar SPSS
2) Vragen met meerdere antwoorden mogelijk worden in 1 kolom weergegeven in de download (Google spreadsheet of Excel)
Onder de video staat de tekstuele uitleg met screenshots! Alleen geïnteresseerd in de Quick Cheat (snelle oplossing voor gevorderde)? Onderaan de blog vat ik het nog even samen!
Teksten uit Google Forms lezen met SPSS
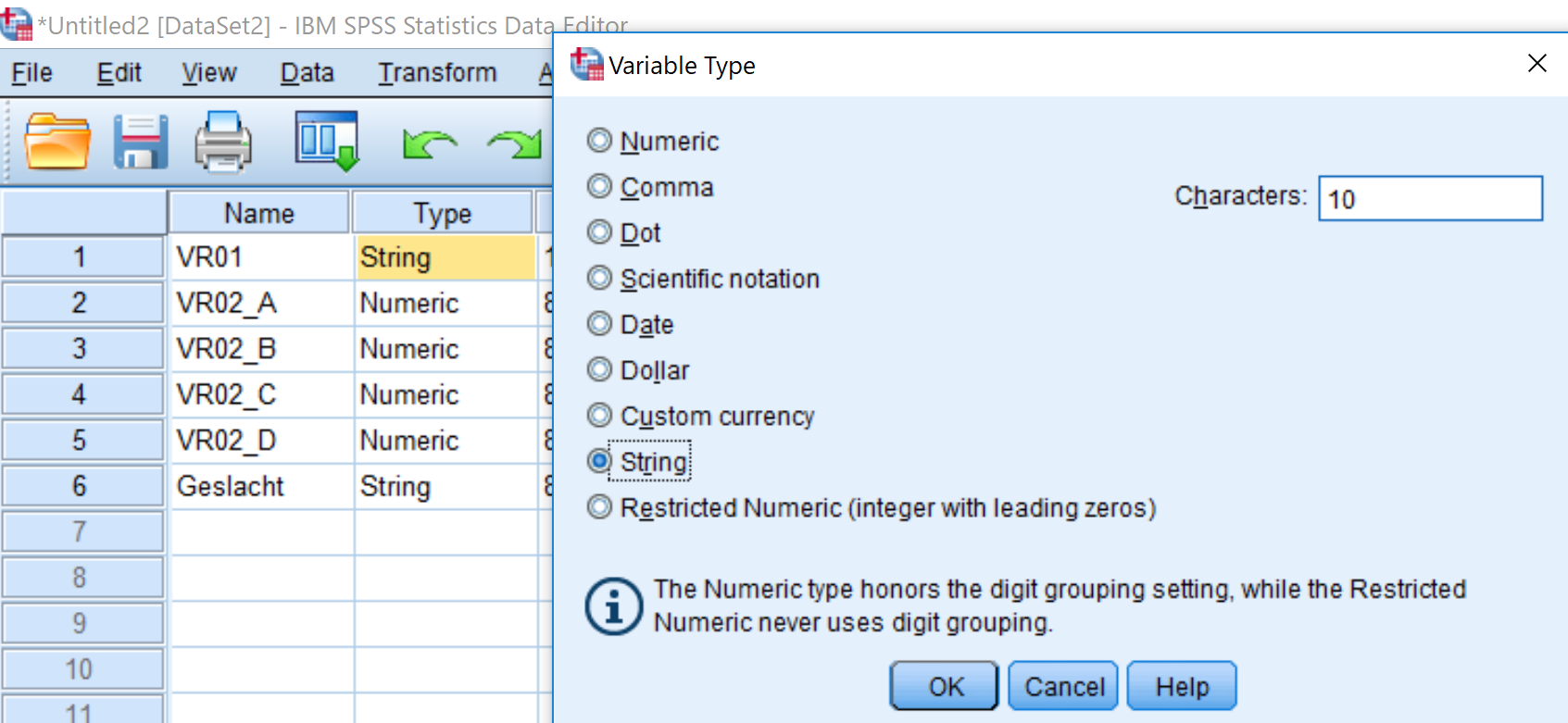
Het feit dat Google Forms de antwoorden op vragen met 1 antwoordmogelijkheid (nominaal of ordinaal) aanbiedt in tekst is op zich geen probleem. SPSS kan hier prima mee omgaan. Op onze website bespreken we dit bij data invoer en het verwerken van open antwoorden. Het meest belangrijke is dat je zorgt dat het Type op het tabblad Variable View op String staat bij de juiste variabele. En dat je zorgt dat het aantal Characters voldoende is om elk antwoord te kunnen inlezen. Zolang Type op Numeric staat kan SPSS het antwoord niet lezen.
Google Forms zet alle antwoorden in 1 kolom
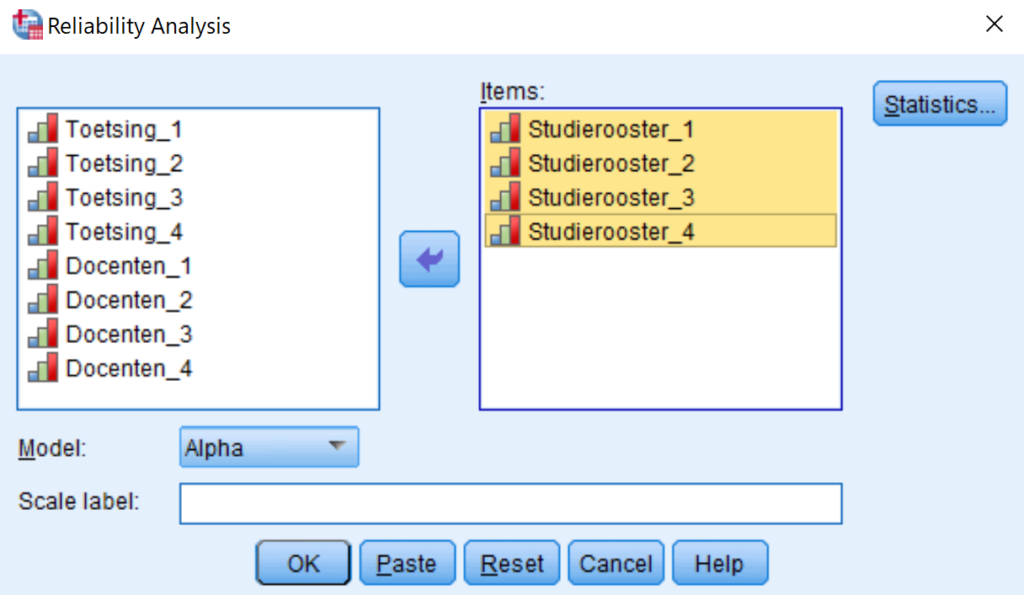
Dit probleem is niet zo simpel op te lossen. Maar daarvoor hebben we een oplossing bedacht. Als voorbeeld nemen we de onderstaande vragenlijst. Hierin stellen we verschillende soorten vragen. Een gesloten vraag met één antwoordmogelijkheid. Een gesloten vraag met meerdere antwoordmogelijkheden en een controle vraag aan het eind.

Als je de antwoorden van de respondenten bekijkt via de spreadsheet van Google Forms dan ziet dat eruit zoals in de onderstaande afbeelding.
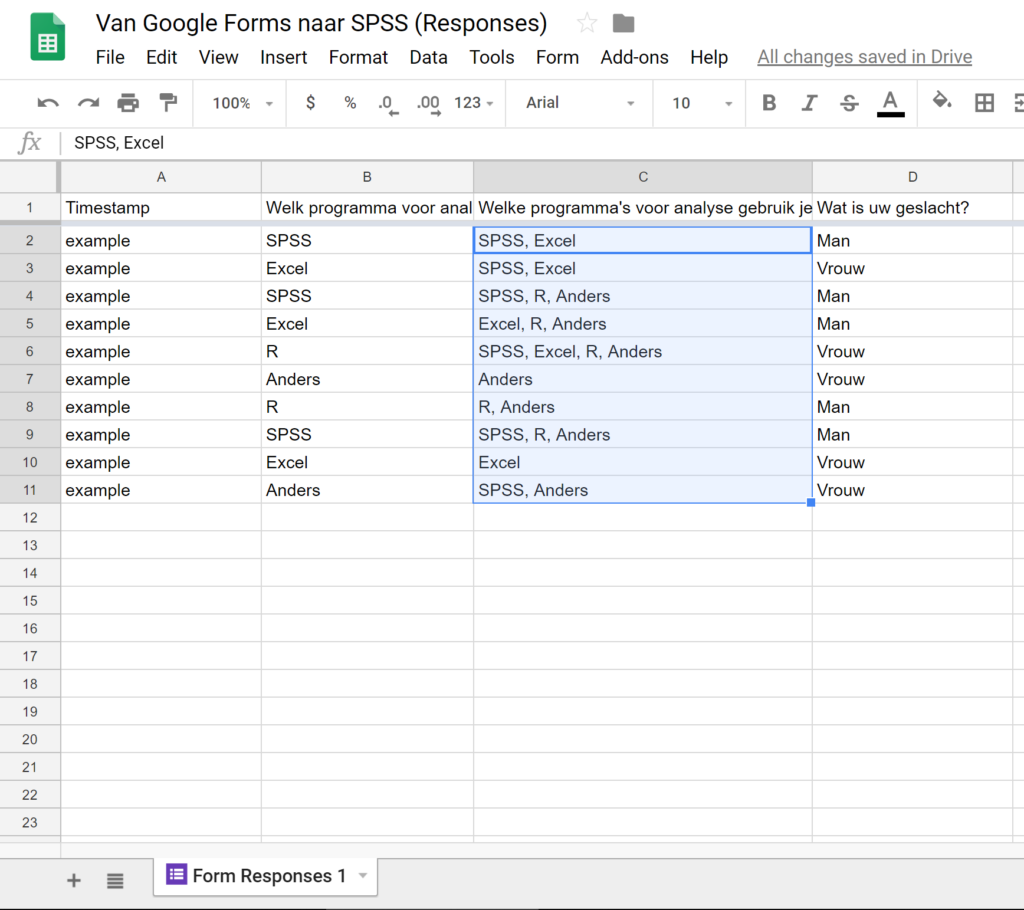
Waarom heeft SPSS hier moeite mee? Zoals gezegd is SPSS gewend dat antwoorden gecodeerd zijn (met nummers). Daarnaast kan het best ook werken met tekstuele antwoorden. Echter kan SPSS niet in één kolom meerdere antwoorden onderscheiden en er dan ook nog een zinnige analyse van maken. Dit moeten we dus gaan oplossen en hiervoor doorlopen we 5 stappen.
Stap 1: Ruimte maken
Om de antwoorden vanuit 1 kolom te verspreiden over meerdere kolommen, moeten we ruimte maken. Er zijn 4 antwoordmogelijkheden. De oorspronkelijke kolom wordt ook gebruikt, dus we maken 3 nieuwe kolommen aan via de optie insert 1 left.

Stap 2: Verspreiden van antwoorden
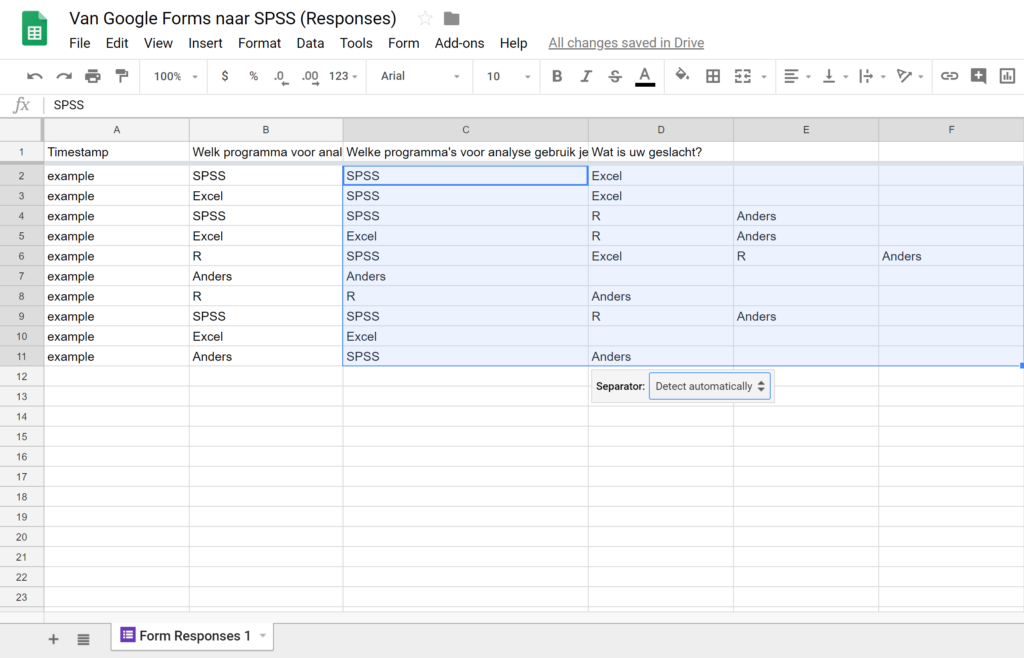
Selecteer de kolom waarin de antwoorden momenteel staan en selecteer (via het menu Data) de optie Split tekst to columns… (In het Nederlands heet deze optie tekst opsplitsen in kolommen (via het menu: Gegevens)).

De antwoorden worden nu verspreid (zie afbeelding hieronder). Nu zie je ook meteen waarom je eerst ruimte hebt gemaakt. Anders had het programma gewoon over geslacht heen geschreven. (Echt waar, probeer maar…. Wij leren ook door trial and error).
Stap 3: Ruimte maken voor codering
SPSS kan nog altijd niets met deze data. Dit komt omdat er in 1 kolom meerdere verschillende opties staan (bijvoorbeeld in kolom E staan Anders en R). We gaan 4 nieuwe kolommen aanmaken waarin data komt te staan die SPSS wel kan lezen. Elke kolom krijgt zijn eigen antwoordoptie uit de oorspronkelijke vraag (dus SPSS, Excel, R, Anders).
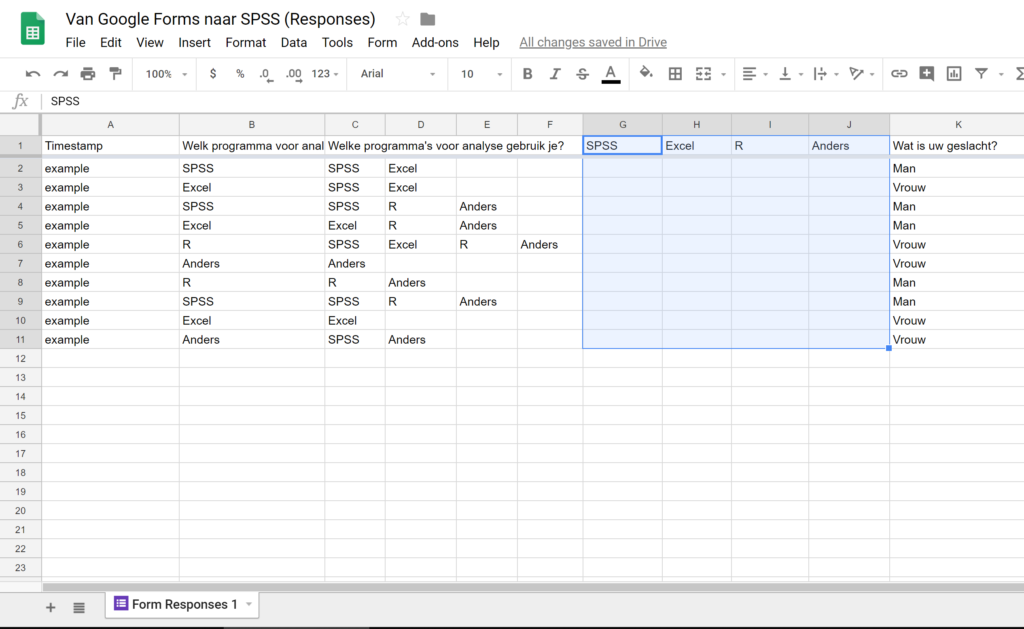
Stap 4: Omzetten naar een nominale (wel/niet) variabele
Nu gaan we met behulp van een kleine formule de spreadsheet of Excel zelf voor ons het werk laten doen. We beginnen met de eerste respondent bij SPSS. We typen het =-teken en daarna countif (in het Nederlands en in Excel: Aantal.Als). We moeten nu twee dingen aangeven.
1: range, dat wil zeggen: welke kolommen kunnen we de antwoorden vinden (C t/m F, regel 2)
2: criterion: dat wil zeggen: aan welke eis moet het voldoen voordat we kunnen optellen (in dit geval moet de formule het woord “SPSS” vinden)
Om het juiste te laten gebeuren én om het ons straks gemakkelijker te maken, vullen we het volgende in

Het dollarteken wordt gebruikt om de kolom naar keuze (C en F in dit geval) vast te zetten als we gaan kopiëren. En dat is handig, want alle antwoorden bevinden zich in deze kolommen. De regel (regel 2) zetten we niet vast omdat we straks de formules gaan kopiëren in de overige regels.
Nu we dit gedaan hebben, kopiëren we de formule naar de volgende kolom (die van antwoordoptie: Excel) en veranderen de formule een klein beetje, zodat alle antwoorden van Excel worden opgeteld.

Uiteraard doen we dat ook voor antwoordoptie “R” (=countif($C2:$F2,”R”)) en in de kolom voor antwoordoptie “Anders” (=countif($C2:$F2,”Anders”)). Elke keer als je klaar bent met een formule en je drukt op Enter dan zie je dat er een 0 (niet geantwoord) of een 1 (wel geantwoord) komt te staan.
En nu gaat het heel snel. Want we kunnen de eerste rij met formules kopiëren en plakken bij alle respondenten. Dit kan in 1x. Als je dat gedaan hebt ziet het er als volgt uit: een bestand dat SPSS kan lezen.

Stap 5: Kopieer de juiste kolommen naar SPSS
De laatste stap is wel een belangrijke om bij na te blijven denken! Je hoeft enkel de kolommen te kopiëren naar SPSS die je zojuist hebt aangemaakt. (en vraag 1 en vraag 3 natuurlijk). Zorg ervoor dat je bestand klaar is om de data te ontvangen. Variable View moet goed worden ingevuld (zie video en screenshot hieronder). Kopieer de antwoorden vanuit de spreadsheet per kolom (of meerdere) tegelijk en zet ze in de juiste kolom in Data View.

In deze afbeelding zie je ook meteen dat bij de eerste en de laatste vraag gekozen is voor Type: String zodat SPSS dit gewoon kan lezen.
Samenvatting (Quick Cheat)
Een oplossing voor het kopiëren van de tekstuele antwoorden in Google Forms kan op twee manieren.
Bij vragen met 1 antwoordmogelijkheid per respondent moet je er voor zorgen dat het Type (in tabblad Variable View) op String staat en dat het aantal Characters voldoende is om elke antwoordoptie te kunnen ontvangen. In principe kun je nu gewoon je analyses doen met deze vraag.
Bij vragen met meerdere antwoordmogelijkheden per respondent moet je een vijf tal stappen nemen:
- Maak ruimte in je spreadsheet voor het splitsen van je antwoordopties;
- split de antwoorden in de spreadsheet naar meerdere kolommen (text to columns / tekst naar kolommen);
- maak daarna weer nieuwe kolommen aan per antwoordmogelijkheid;
- laat via een formule per respondent optellen of het antwoord wel of niet gegeven is (0 of 1);
- kopieer enkel de nieuwe kolommen naar SPSS en zorg dat de data daar ontvangen kan worden.
Heb je een snellere manier ontdekt? Laat het ons weten! Meer tips? Check geregeld ons blog en volg ons op Facebook en Instagram.